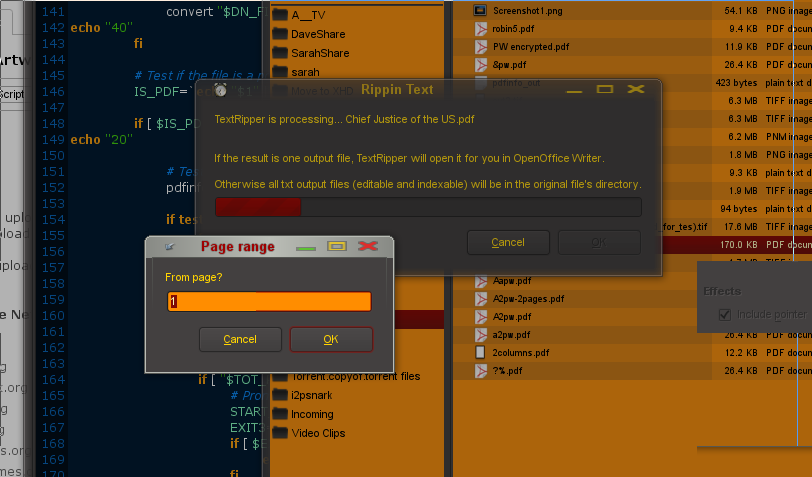
Description: An OCR, Optical Character Recognition, gui application or cli script # Supports the Tesseract engine by default! # Optionally supports the Ocrad engine for multi-column text. # These recognition engines have a very high character recognition success rate compared to other OCR's, including proprietary software. # New: multi-page and multiple file selection support! # Enhanced XSANE output and TIFF compatibility. # New: now handles nearly any format out there! # This script will convert any image of text into editable and indexable text. (for a full list of compatible file formats see the first filter below) # # REM: The better/cleaner/higher contrasted/higher resolution your image or scan is the better the results # # Dependencies: libtiff-dev (or -devel)(installed FIRST), tesseract-2.04 (latest stable-version), your chosen language data for Tesseract (2.00 and up) *1, # ImageMagick, ghostscript, Zenity, and OpenOffice or other text editor *2 # This version of tesseract can be downloaded from here: http://code.google.com/p/tesseract-ocr/downloads/list # Warning: This script will not work with the latest beta version (tesseract 3.00 pre-release) due to database structure modifications. # # Optional dependencies: ocrad ->an alternate recognition engine # If inital results are unsatisfactory, maybe this engine will do better. Most importantly, it supports basic page format recognition. *3 # The latest version of ocrad can be downloaded off the GNU mirror list here: http://www.gnu.org/software/ocrad/ # # Also: Make sure to select Unicode UTF-8 in OpenOffice's pop-up window (or text editor of your choice). # # # # *1 Install Tesseract after libtiff-dev. Then extract all the language databases you need into the "wherever_you_installed/tesseract-2.04/tessdata" directory. # This is done automatically if you extract the language databases from WITHIN the "tesseract-2.04" directory (and allow overwriting). # This script allows the use of multiple language databases. Default is English and French. For adding others see comments below. # You NEED at least one language database or tesseract will not work. # *2 Simply change the occurance of "soffice -writer" below to a text editor of your choice, ie: gedit, KWrite, etc # Some systems call on OpenOffice Writer differently. If unsure, check the properties tab of your Writer launcher. # Ie: On customized versions of OOo (such as the ones provided by Linux Mandrake or Gentoo), you start Writer with: oowriter # *3 If you install ocrad also, TextRipper will recognize this and prompt you to choose between the two offering better recognition or page format support # # Troubleshooting: # If this script ends saying your text editor can't open "OCR output-editable text.txt", # or if run off the cli: Unable to load unicharset file /usr/local/share/tessdata/eng.unicharset # do (as superuser): # echo /usr/local/share /usr/share | xargs -n 1 cp -R wherever_you_installed/tesseract-2.04/tessdata # Explanation: Tesseract may call on the tessdata directory from the /share directory of your filesystem, # so you need to make your language databases available from there.
I am getting this error
/home/christoph/Downloads/dog_petition10001.jpg (editable and indexable 001.txt does not exist
And I believe I installed everything correctly.
I have Zenity, Tesseract-ocr, Tesseract-ocr-eng, imagemagick, libtiff4-dev, ghostscript.
Any help would be appreciated. I have tried it on different images in different formats, jpg, png, pdf. Same error for all
hey polardude
try this:
do (as superuser):
# echo /usr/local/share /usr/share | xargs -n 1 cp -R wherever_you_installed/tesseract-2.04/tessdata
Explanation: Tesseract may call on the tessdata directory from the /share directory of your filesystem,
so you need to make your language databases available from there.
let me know if this was it.
d.
Just run the script off the command line once you've installed the dependancies.
ps to all users: there's a great new one out there called YAGF. check it out.
Uh, it's not really. Try again.
HOWEVER, soon, very soon, I'll release the new version of Text Recognition now rebaptized TextRipper. It can rip text off anything!
till then,
d.
Hi D,
Well when I clicked on "Download", I have a new page coming up saying that the download popup should appear soon. But instead, no popup appears and it redirects me to the following link:
http://gtk-apps.org/CONTENT/content-files/132759-Text%20Recognition
Any insight regarding this? Thanks,
just copy/paste it into a file, add the execute permissions, then read through the comments to ensure dependencies, etc.
Otherwise, like i said above, in about a week i'll release TextRipper.
Thanks for the fast reply. I appreciate it.Guess I'll wait for the product if it really can rip any text!
Btw, does it handle hand-written cases? Most OCR out there (including Tessract) cannot handle hand-written characters. From my understanding, Tessract expects a well-segmented and well-defined fonts.
Cheers
Hello Kayce:
the main difficulty in recognizing handwritten text has less to do with the "font" (caligraphy) but rather whether the letters are joined or distictly separate. Tesseract does a pretty fine job if the letters aren't linked. Try it out for yourself. If you find an engine that beats tesseract in this please let me know.
dave
Hello Kayce:
the main difficulty in recognizing handwritten text has less to do with the "font" (caligraphy) but rather whether the letters are joined or distictly separate. Tesseract does a pretty fine job if the letters aren't linked. Try it out for yourself. If you find an engine that beats tesseract in this please let me know.
dave
When I right click an image file, and after selecting "English", I only get this message:
/home/me/Tmp/OCR output-editable text.txt does not exist.
This occurred in both versions of your script. I don't understand.
Thanks in advance.
tjc:
There are only two possible causes for this error message.
The first is treated clearly albeit concisely in the heading comments of the script itself under troubleshooting.
The second is an incompatible image format because either 1) you are missing libraries such as libtiff-dev or 2) the tesseract engine just can't treat that particular file. In this case a conversion usually fails. You must rescan preferrably to a different format such pnm. There have also been reports of success in such cases after switching to the ocrad engine.
Your pick.
cheers,
d.
Thanks for the info. I believe my issue was with not having tesseract-ocr and tesseract-ocr-eng installed. I just installed those and voila. I wasn't aware there were dependencies for it as none were mentioned on this page, so that's why. hehe. Thanks. I figured it out now. Although, not sure about libtiff-dev. It's not in Ubuntu's repos, but is in Debian's. Doesn't seem I need it installed though.
You might want to check out tessereract OCR as your recognition engine - just using the data in ubuntu's repo I was able to recognise stuff that ocrad completely failed with...




















Ratings & Comments
19 Comments
I am getting this error /home/christoph/Downloads/dog_petition10001.jpg (editable and indexable 001.txt does not exist And I believe I installed everything correctly. I have Zenity, Tesseract-ocr, Tesseract-ocr-eng, imagemagick, libtiff4-dev, ghostscript. Any help would be appreciated. I have tried it on different images in different formats, jpg, png, pdf. Same error for all
hey polardude try this: do (as superuser): # echo /usr/local/share /usr/share | xargs -n 1 cp -R wherever_you_installed/tesseract-2.04/tessdata Explanation: Tesseract may call on the tessdata directory from the /share directory of your filesystem, so you need to make your language databases available from there. let me know if this was it. d.
I installed all the dependencies and the optional one as well, but how do i install the script ?
Just run the script off the command line once you've installed the dependancies. ps to all users: there's a great new one out there called YAGF. check it out.
i can finally use scanned papers and pdfs for editing! thank you, flawless even for pdf and tiff
Glad to hear your raves.
Hello, The download link is broken. Can somebody fix it please? Thanks.
Uh, it's not really. Try again. HOWEVER, soon, very soon, I'll release the new version of Text Recognition now rebaptized TextRipper. It can rip text off anything! till then, d.
Hi D, Well when I clicked on "Download", I have a new page coming up saying that the download popup should appear soon. But instead, no popup appears and it redirects me to the following link: http://gtk-apps.org/CONTENT/content-files/132759-Text%20Recognition Any insight regarding this? Thanks,
just copy/paste it into a file, add the execute permissions, then read through the comments to ensure dependencies, etc. Otherwise, like i said above, in about a week i'll release TextRipper.
Thanks for the fast reply. I appreciate it.Guess I'll wait for the product if it really can rip any text! Btw, does it handle hand-written cases? Most OCR out there (including Tessract) cannot handle hand-written characters. From my understanding, Tessract expects a well-segmented and well-defined fonts. Cheers
Hello Kayce: the main difficulty in recognizing handwritten text has less to do with the "font" (caligraphy) but rather whether the letters are joined or distictly separate. Tesseract does a pretty fine job if the letters aren't linked. Try it out for yourself. If you find an engine that beats tesseract in this please let me know. dave
Hello Kayce: the main difficulty in recognizing handwritten text has less to do with the "font" (caligraphy) but rather whether the letters are joined or distictly separate. Tesseract does a pretty fine job if the letters aren't linked. Try it out for yourself. If you find an engine that beats tesseract in this please let me know. dave
I've uploaded TextRipper and just wanted to let you know. I hope it satisfies you as much as it satisfies most everybody. d.
When I right click an image file, and after selecting "English", I only get this message: /home/me/Tmp/OCR output-editable text.txt does not exist. This occurred in both versions of your script. I don't understand. Thanks in advance.
tjc: There are only two possible causes for this error message. The first is treated clearly albeit concisely in the heading comments of the script itself under troubleshooting. The second is an incompatible image format because either 1) you are missing libraries such as libtiff-dev or 2) the tesseract engine just can't treat that particular file. In this case a conversion usually fails. You must rescan preferrably to a different format such pnm. There have also been reports of success in such cases after switching to the ocrad engine. Your pick. cheers, d.
Thanks for the info. I believe my issue was with not having tesseract-ocr and tesseract-ocr-eng installed. I just installed those and voila. I wasn't aware there were dependencies for it as none were mentioned on this page, so that's why. hehe. Thanks. I figured it out now. Although, not sure about libtiff-dev. It's not in Ubuntu's repos, but is in Debian's. Doesn't seem I need it installed though.
You might want to check out tessereract OCR as your recognition engine - just using the data in ubuntu's repo I was able to recognise stuff that ocrad completely failed with...
Chris: Thanks for your input. You'll be happy with Ver 1.1. It's made for tesseract but still allows for ocrad if you like. cheers, d.