





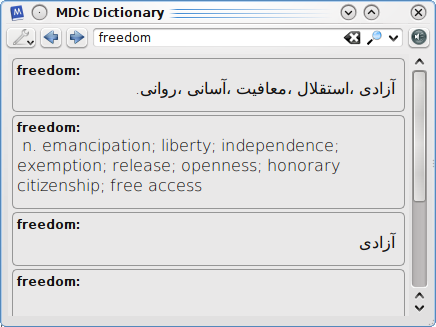
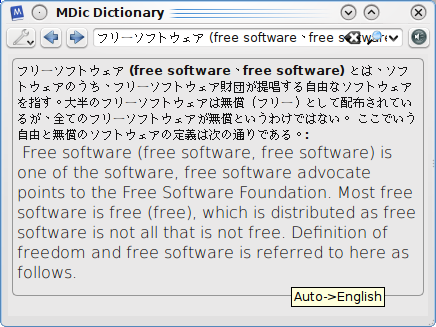
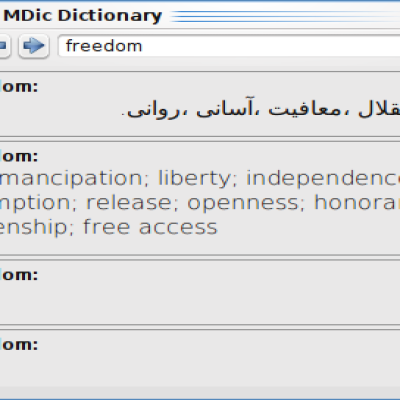
You have to only select (or highlight) a word to view its meaning on the screen.
MDic is able to pronounce the words by default if espeak tool is installed, and for KDE users with kttsd. It is also possible to use Babylon glossaries (.bgl) , Stardict dictionaries (.ifo) , Freedict dictionaries (.tei) and Sdictionary dictionary (.dct) by converting them via "mdicconv" convertor or PyGlossary tool.
The pre-requirements to use MDic is Qt4 and GNU Aspell library.
you can use MDic on both KDE or GNOME Desktop Environments.
News:
(12-Feb-2010) MDic 0.8.1 released.
(07-Oct-2009) MDic 0.8 released.
(22-Nov-200
 MDic 0.6.3 released.
MDic 0.6.3 released.(11-Aug-200
PyGlossary add support for MDic dictionaries.(29-Jul-200
MDicConv 0.2.6.1 released.(29-Jul-200
MDic 0.6.1 Debian etch package is ready.(22-Jul-200
MDic 0.6.1 released.feel free to email us to mehrdad.momeny[AT]gmail.com or thinkgnu@gmail.com or leave comments here...









Ratings & Comments
26 Comments
while ((word2find[word2find.length()-1] < 64) || (word2find[word2find.length()-1] < 97 && word2find[word2find.length()-1] > 90) || (word2find[word2find.length()-1] > 122 && word2find[word2find.length()-1] < 128)) { //for remove characters after word like ; . or ... http://www.methoo.com
In KDE 4.5.2 (Kubuntu 10.10) when the mdic icon is hidden in the system tray the text that is supposed to be beside the mdic icon instead overlaps with the top item in the hidden list.
When using KDE Popup the notification has a fixed size of about two lines. This makes any additional text unreadable and thus makes KDE Popup unusable. This in KDE 4.3.5.
Can this dictionary be used offline or does one require an internet connection?
There are 2types of dictionaries to add! One online (Using Google translate) And other one is offline (mdic dictionaries) check this out: mdic.gnufolks.org/dictionaries.html
Hi, I really like this app. The integration into kde is perfect and it is fast. But I have some problem with german to english dictionaries. Some words must be searched with the first letter in uppercase, like "Markt" There is so corresponding word in lowercase. This would not be a problem, if the system would return a result anyway, but this does not happen. The database file seams to be correct and contains "uppercase"-words. Is here something wrong with the sql query? I would support to bugfix this. cheers Martin
Hmm, Changing queries to search case insensitive makes mdic speed too low! I'm about to make another way for you!
Hi, great to hear. I am also programming a bit a solved it, be passing the unprocessed string to the dict engines. Here I correctet the character checking and first run the dict engines. If there is no result, I make a lower case version and run the engines again: Here is the changed code: while ((word2find[0] != '@') && ((word2find[0] < 64) || (word2find[0] < 97 && word2find[0] > 90) || (word2find[0] > 122 && word2find[0] < 128))) { //for remove characters before word like ; . or ... except @ (we need @ for related words link in babylon databases) if (word2find.size() == 1) return result; word2find.remove(0, 1); } while ((word2find[word2find.length()-1] < 64) || (word2find[word2find.length()-1] < 97 && word2find[word2find.length()-1] > 90) || (word2find[word2find.length()-1] > 122 && word2find[word2find.length()-1] < 128)) { //for remove characters after word like ; . or ... if (word2find.size() == 1) return result; word2find.remove(word2find.length() - 1, 1); } ... and .... if (mainWord != mainWord.toLower()) { // nothing found, now make the main word to lower word2find = word2find.toLower(); mainWord = word2find; continue; } else ........ may be it helps. Thanks for this great dict. Martin
Hi MTux, Where did you get the English Urdu Dictionary. I have been searching for a good free English-Urdu dictionary. Please give the link to the English urdu dictionary. thanks.
Hello! Very useful application you have there! Installed it today and I've used it several times already! Is it possible to convert the free gcide and wn dictionaries? I have tried to unzip them using dictunzip and I have tried converting them using dictconvert and pyglossary, with no success. I am not sure what format these dictionaries are in so that might help :P Btw. I'm on Kubuntu with KDE 3.3.2
... that should of course be kde 4.3.2 and nothing else ...
PyGlossary is a separate project aiming to support multiple dictionary types! It's better to ask his developer to support this :D http://ospdev.net/projects/glossary-pywork/
Sounds reasonable! Thanks again for a cool and useful piece of software :)
The best dictionary out thee for linux. The System tray popup feature is awesome
for some reason, converter could not convert any stardict dictionaries I have.
first extract .tar.gz file. some of stardict dictionaries' .dict file compressed with dictzip tool, you'll have to decompress them before converting. after install "dictzip" use: $ dictunzip file.dict.dz OR: $ dictzip -d file.dict.dz (two shape of app!) function to embed this on MDicConv, will be added soon.
Thanks. Now I have the crash, though. like that: (gdb) run -o Mueller7GPL.m2 Mueller7GPL.ifo Starting program: /usr/local/bin/mdicconv -o Mueller7GPL.m2 Mueller7GPL.ifo [Thread debugging using libthread_db enabled] [New Thread 0x7f4ea763f6f0 (LWP 1084)] [New Thread 0x4144b950 (LWP 1087)] [Thread 0x4144b950 (LWP 1087) exited] [New Thread 0x42041950 (LWP 1088)] [Thread 0x42041950 (LWP 1088) exited] Program received signal SIGSEGV, Segmentation fault. [Switching to Thread 0x7f4ea763f6f0 (LWP 1084)] 0x0000000000424acf in StarDict::search (this=0x69da60, word=0x69f788 "'cause") at stardict.cpp:313 313 for(uint a = startChunk; a < endChunk + 1; a++ ) chunkLen += offsets[a]; (gdb) show a Ambiguous show command "a": annotate, architecture, args, auto-solib-add. (gdb) a? Ambiguous command "a?": . (gdb) print a $1 = 0 (gdb) print offsets[a] $2 = (long unsigned int &) @0x0: <error reading variable> (gdb) print endChunk $3 = 0 (gdb) print chunkLen $4 = 0 (gdb) print offset $5 = 72904364020203533 (gdb) print offsets $6 = {<std::_Vector_base<long unsigned int,std::allocator<long unsigned int> >> = { _M_impl = {<std::allocator<long unsigned int>> = {<__gnu_cxx::new_allocator<long unsigned int>> = {<No data fields>}, <No data fields>}, _M_start = 0x0, _M_finish = 0x0, _M_end_of_storage = 0x0}}, <No data fields>} (gdb) print offsets.size $7 = {size_t ( const std::vector<long unsigned int,std::allocator<long unsigned int> > *)} 0x4273d4 <std::vector<unsigned long, std::allocator<unsigned long> >::size() const> (gdb) print offsets.size() $8 = 0 (gdb)
sorry, this output doesn't help me! :( please paste command line output!
command line output is : Segmentation fault.
well, the output means, that in file stardict.cpp , in line 313, you are trying to get value of first element in vector offsets, but the vector is empty.
Oh! as you know, that part of code was written by another one! and i don't have any idea about it. :( I think it's better to report it to main developer: Raul Fernandes "rgfbr[AT]yahoo.com.br"
Now, you can use PyGlossary instead of MDicConv. get it here: http://ospdev.net/projects/glossary-pywork
The BEST Dictionary App in Linux !! Thanks ... Feature Request : the ability of word selection in pdf or image files ...
I forgot to say. I hope some OCR functionality to be added to this app,soon. This app can be #1 dictionary software for Linux.
Really nice! I wish I could rate "good" more than once.